
Discover How Mistral Large 2, Claude 3.5, GPT-4o and Gemini 1.5 Pro Stack Up in an Addition Accuracy Test
Evaluating the Performance of Leading AI Models in Handling Long Sequences of Single-Digit Numbers
AI chatbots differ in their ability to handle long calculations involving single-digit numbers. This study aims to evaluate how effectively various AI models can add extended sequences of single-digit numbers. While LLMs are not designed to be calculators, understanding their limits in addition can provide valuable insights.

Method
I tested four leading AI chatbots—Mistral Large, Anthropic’s Claude 3.5 Sonnet, OpenAI’s GPT-4o and Google Gemini 1.5 Pro—to determine which one performs best in adding sequences of single-digit integers. Each model was assessed for its accuracy in adding these sequences.
Mistral was tested in two versions: its previous version and the newest version, Large 2 (which was released yesterday! 🚀). This comparison allows us to measure any improvements in performance.
The goal is to determine the maximum length of digit sequences that each chatbot can add accurately. We started with short sequences and increased their length to find the limit of each model’s accuracy.
Sequences were randomly generated using a Python program. Each sequence length was tested five times with different sets of numbers to evaluate whether the chatbot fell into the Accurate, Hit-or-Miss or Inaccurate zones.
Results
Different models exhibited varying accuracy thresholds. Mistral Large performs best with sequences of up to 8 digits, consistently providing accurate results. Beyond this length, its accuracy declines and becomes inconsistent. For sequences between 8 and 15 digits, Mistral Large can be accurate some of the time. However, for sequences longer than 15 digits, Mistral Large falls into an Inaccuracy zone and consistently provides incorrect answers.
The latest Mistral Large 2 shows significant improvement. It can now handle sequences up to 101 digits before entering the Inaccuracy zone, compared to just 15 digits of Mistral Large.
Google Gemini 1.5 Pro is also accurate with sequences up to 8 digits but becomes consistently inaccurate with sequences longer than 22 digits.

Claude 3.5 Sonnet accurately added sequences up to 49 digits. Between 49 and 118 digits, its accuracy was inconsistent, and beyond 118 digits, it consistently provided incorrect results.
OpenAI’s GPT-4o accurately added sequences up to 74 digits long. It could manage sequences up to 671 digits, but its accuracy dropped when sequences were longer than 74 digits. For sequences longer than 671 digits, it became unreliable and entered the Inaccuracy zone.
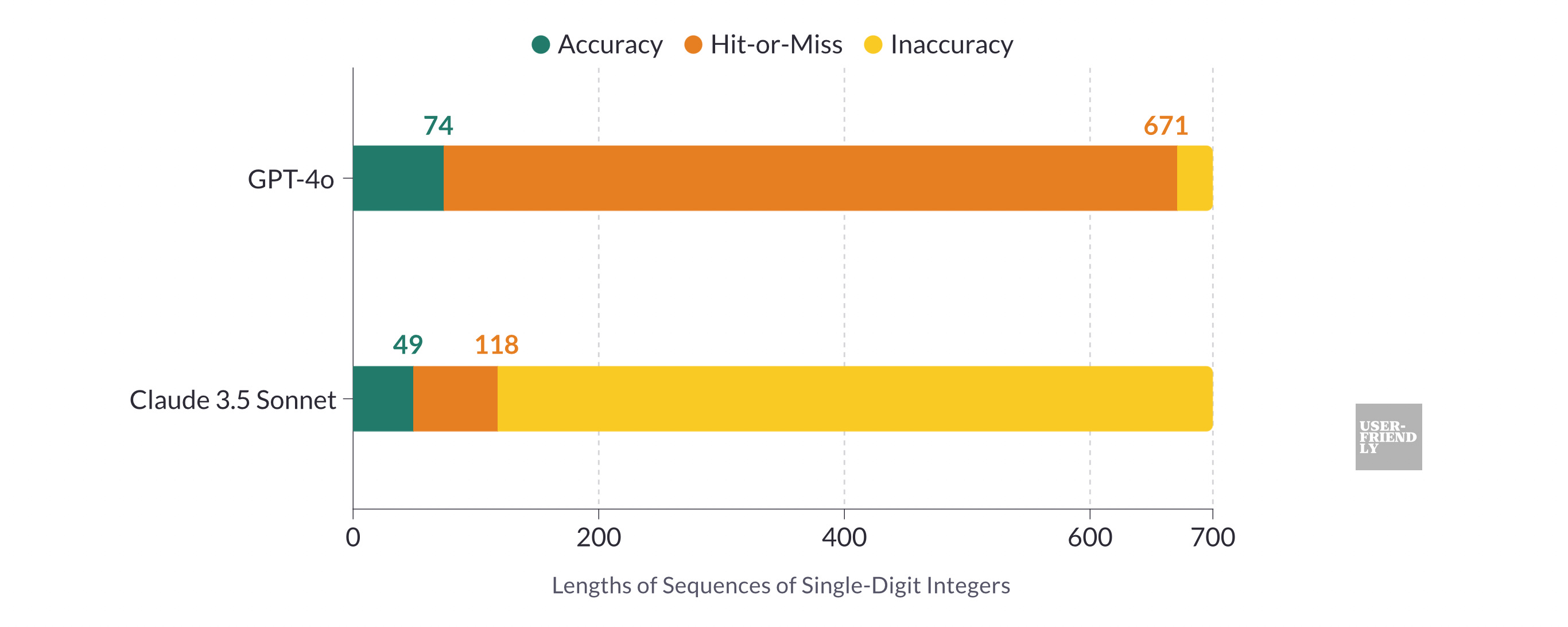
In summary, GPT-4o is the most capable for addition tasks, accurately handling the longest sequences of single-digit numbers before entering the Inaccuracy zone. Claude 3.5 Sonnet ranks second, accurately adding sequences up to 118 digits. The latest Mistral Large 2 follows, demonstrating good performance but not as strong as Claude 3.5 Sonnet. Google Gemini 1.5 Pro and the previous version of Mistral are the least capable, as they accurately handle only shorter sequences of digits.

Conclusion
When using AI chatbots to calculate long sequences of numbers, it is important to be aware of their accuracy limits. This study specifically examined the addition of single-digit numbers. However, the accuracy of other operations, such as multiplication or handling double-digit numbers, might vary. Future research should explore these aspects to better understand the limitations of LLMs.