
Evaluating Claude 3.5, GPT-4o and Gemini 1.5 Pro: How Well Do They Extract Information and Count Items?
Testing LLMs for information extraction and item counting
Frontier models now have longer context windows, enabling users to contextualize interactions by uploading their own documents. But how good are they at extracting information? In this test, we will evaluate three leading LLMs: Anthropic’s Claude 3.5 Sonnet, OpenAI’s GPT-4o and Google’s Gemini 1.5 Pro.

Method
The three LLM are tasked with extracting information from a document containing a list of job titles. The LLMs were required to identify distinct job titles, group them accordingly and determine the count for each job title. The prompt used for this task is as follows:
Analyze the attached document containing job titles. For each unique job title:
1. Count the number of employees
- Think through this step by step; show your steps.
- Find and count rows for each job title (1 job title = 1 employee).
- Sum the counts to determine the total number of employees for each job title.
2. Present the results in a table format with these columns:
- No (serial number)
- Job Title (Example: Chief Technology Officer, Manager, etc.)
- Number of Employees
You must:
- Double-check each row individually.
- Use a systematic method (e.g., striking out counted rows).
- Be extra cautious with non-consecutive, similar roles.
- Think through step by step, as accuracy is top priority.
To verify the accuracy of your output:
1. Add up the numbers in the ‘Number of Employees’ column in your table.
2. Show your step-by-step calculation.
3. The total should match the attached document. If not, review the document again for any missed entries.The LLMs were tested on two dimensions:
Listing format: One list in a somewhat randomized, non-alphabetically order, and another list in alphabetical order
List length: Four sets of lists with 100, 75, 50 and 25 job titles.
Below are examples of an alphabetically ordered list (left) and a non-alphabetically ordered list (right):


Each LLM was tested on alphabetical lists with 100, 75, 50 and 25 records, follow by non-alphabetical list with 100, 75, 50 and 25 records. Results were captured after a single prompt was sent to the LLM.
Results
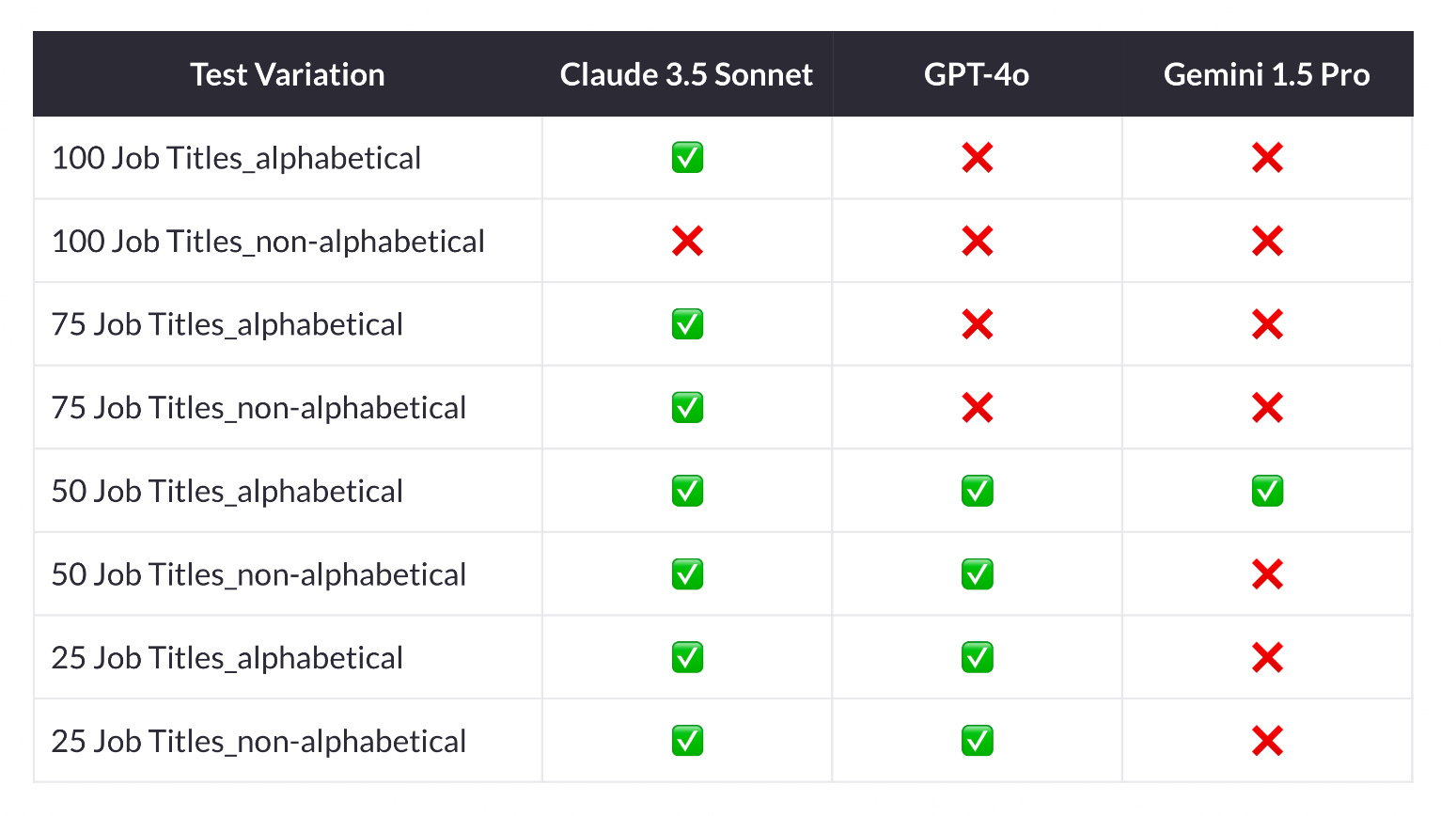
The best performer was Claude 3.5 Sonnet, achieving 100% accuracy of information extraction in 7 out of 8 tests. It only failed on the non-alphabetical list with 100 records.
GPT-4o achieved 100% accuracy only for lists of 50 records and below. It failed to achieve 100% accuracy for lists with 75 and 100 records, both alphabetical and non-alphabetical. Gemini 1.5 Pro performed the worst comparatively. During the test runs, it only achieved 100% accuracy for the alphabetical list of 50 records.
While all LLMs accurately extracted all job titles listed in the source document, they struggled with determining the counts of each job title.
The table shows a summarizes of test results, where ✅ indicates 100% accuracy and ❌ indicates less than 100% accuracy:
The table below shows the number of errors made by the LLMs during testing, specifically related to incorrect counts of job titles.

Key Takeaways
Even with long context windows, such as Gemini 1.5 Pro with 2 million input tokens, LLMs have difficulty extracting and processing long lists to perform item counts. This task, which can be easily done in a spreadsheet, appears to be a hit-or-miss for LLMs.
As more companies use LLMs to connect to internal data, they must be clear about their acceptable error tolerance levels for LLM output. For companies with low tolerance for errors, high output accuracy can be achieved through a combination of model fine-tuning, search-retrieval setup (RAG), and advanced prompting techniques.
